

破解 SEO 核心:Google 爬蟲運作全解析,新手也能輕鬆懂
[ez2_pageview]
[ez2share_buttons title=”分享這篇文章”]
[text_resizer]
網站經營者常聽到「Google 爬蟲」,但它到底是什麼?
為什麼有些網站剛上線就能被 Google 快速收錄,而有些則遲遲無法被搜尋?
其實,掌握 Google 爬蟲的運作邏輯,就是掌握 SEO 的核心。
本文將帶你從新手視角,一步步理解 Google 爬蟲的機制、抓取流程與常見問題,讓你能更有效率地讓網站被看見、被收錄、被排名!
你可能會感興趣:SEO是什麼?SEO新手第一課:從零到流量王,征服搜尋引擎
▍Google 爬蟲是什麼?
Google 爬蟲(Googlebot)是一個自動化程式,負責瀏覽並抓取全球網站的內容。
它會像使用者一樣讀取網頁、點擊連結、分析 HTML 結構,並把這些資料送回 Google 的資料庫中。
簡單來說,Googlebot 就是搜尋引擎的「眼睛」,它看得見的內容才有機會被收錄與排名。
▍Google 爬蟲的三大步驟
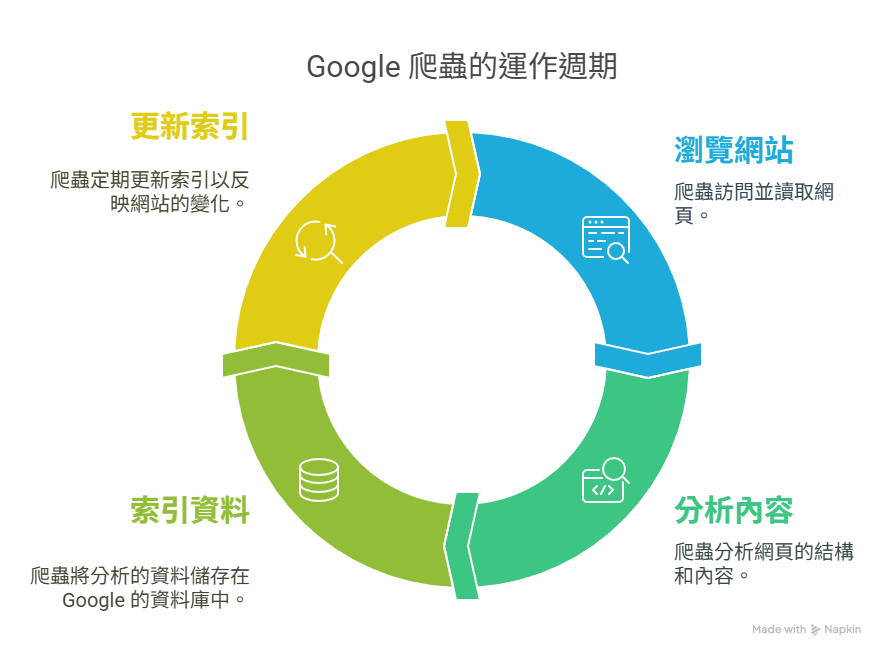
▎抓取(Crawling)
Googlebot 首先會透過 sitemap(網站地圖)或外部連結發現新網頁,並進入這些頁面進行抓取。
若網站結構混亂、無 sitemap 或被 robots.txt 阻擋,Googlebot 可能無法正確找到頁面。
▎索引(Indexing)
抓取後,Google 會根據頁面內容、結構、語意與關鍵字,分析這個頁面在網路上的意義,並決定是否將其納入搜尋結果中。
若內容品質不佳、重複性太高,可能被排除在索引之外。
▎排名(Ranking)
一旦頁面被成功索引,Google 會依據數百項排名因素(例如使用者體驗、關鍵字相關性、外部連結等)來排序,決定使用者搜尋時顯示的頁面順序。
▍如何讓 Googlebot 更容易抓取你的網站?

▎提交 Sitemap
建立並提交 XML 網站地圖(Sitemap)到 Google Search Console,讓 Google 更快速知道你有哪些頁面、哪些更新。
▎優化內部連結結構
將相關頁面用內部連結串聯,形成清楚的主題架構,讓 Googlebot 更容易理解頁面之間的關聯性與重要程度。
▎檢查 robots.txt 設定
確保 robots.txt 沒有錯誤封鎖重要頁面。可以開放給 Googlebot 抓取的頁面路徑應清楚列出,避免誤封首頁或文章清單。
▎提升網站速度與行動版適配
網站速度會影響 Googlebot 的抓取效率,而行動裝置友善則是排名的重要因素。
建議使用 Google PageSpeed Insights 檢測並改善載入表現。
▎避免重複內容與薄弱頁面
Google 不喜歡內容重複或無價值的頁面。
請確保每一頁都有明確主題與豐富內容,並移除空頁或過短的文章。
你可能會感興趣:SEO地雷大揭密:黑帽、白帽、灰帽一次搞懂,不怕網站被懲罰!
▍常見 Googlebot 抓取問題與解法
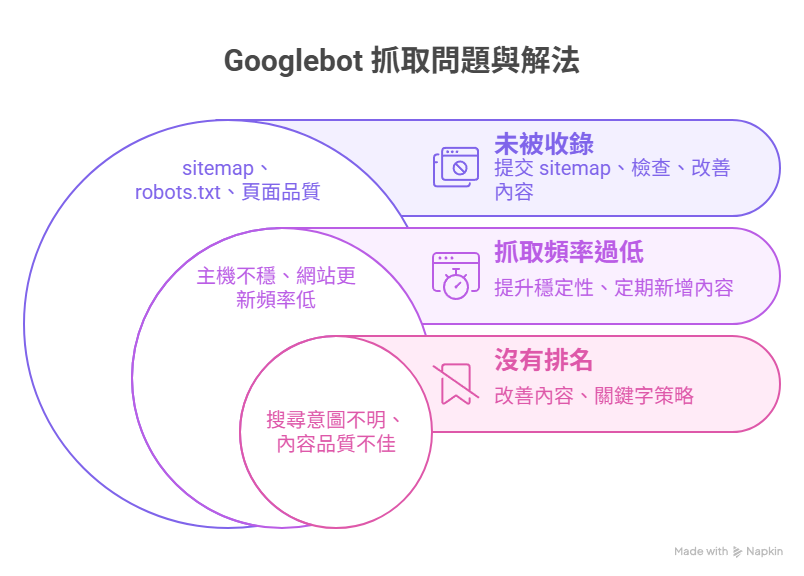
| 問題 | 可能原因 | 解決方式 |
|---|---|---|
| 網站未被收錄 | 沒有 sitemap、robots.txt 阻擋、頁面品質低 | 提交 sitemap、檢查阻擋、強化內容 |
| 抓取頻率過低 | 主機不穩、網站更新頻率低 | 提升網站穩定性、定期新增內容 |
| 被收錄卻沒有排名 | 搜尋意圖不明、內容品質不佳、關鍵字使用錯誤 | 改善內容結構與關鍵字策略 |
▍解決抓取與收錄問題
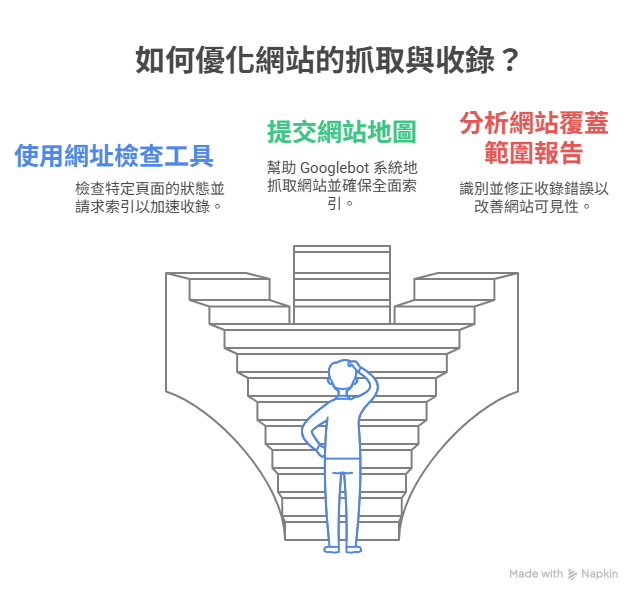
▎網址檢查工具
輸入你想查詢的網址,即可查看該頁面是否已被抓取、是否被索引,並得知 Google 對該頁的最後抓取時間與可見內容。
若頁面尚未收錄,可點選「請求索引」加速處理。
▎網站地圖
可提交或更新 XML Sitemap,幫助 Googlebot 更有系統地抓取網站。
系統會回報提交是否成功,並顯示有多少頁面已被納入索引。
▎網站索引狀態
此報告會列出所有已收錄、尚未收錄、有錯誤或被排除的頁面,並提供原因說明(如重定向錯誤、404、noindex等),方便你快速修正。
▍常見問題 FAQ
什麼是 Google 爬蟲(Googlebot)?
Google 爬蟲是一種自動化程式,負責抓取網頁內容並建立索引,是搜尋引擎理解與收錄網站的關鍵工具。<br>只有被 Googlebot 正確抓取與解析的網頁,才有機會出現在搜尋結果中。
Googlebot 會抓取所有網站內容嗎?
不一定。<br>Googlebot 會根據網站的 sitemap、內部連結、robots.txt 設定等條件進行抓取。<br>如果某些頁面被禁止爬取,或抓取困難(如JavaScript渲染不良),就可能被略過或收錄失敗。
網站多久會被 Googlebot 抓取一次?
抓取頻率依網站權重與更新頻率而定。<br>高流量、更新頻繁的網站通常抓取次數較高。<br>你可以透過 <a href="https://search.google.com/search-console/about" data-type="link" data-id="https://search.google.com/search-console/about" target="_blank" rel="noreferrer noopener nofollow">Google Search Console</a> 查看 Googlebot 的抓取行為紀錄,甚至請求加速索引。
如何確認我的網站有被 Googlebot 抓取?
使用 Google Search Console 的「網址檢查工具」可查詢單一頁面是否已被抓取與索引,還能查看抓取時間與頁面狀態。<br>此外,「網站索引狀態」也能顯示整體網站的收錄情況。
robots.txt 是什麼?會影響 Google 爬蟲嗎?
是的。<br>robots.txt 是用來告訴搜尋引擎哪些頁面可以抓取、哪些不行的設定檔。<br>若不小心封鎖重要頁面,Googlebot 就無法訪問這些內容,進而影響收錄與排名。
▍結論
SEO 並不只是堆關鍵字、做外部連結,而是從根本理解 Google 的工作方式開始。Googlebot 就是你網站的「第一位讀者」,你必須讓它讀得懂、讀得順、讀得快,才能進一步打動演算法並獲得好排名。
透過優化結構、提交 sitemap、維護網站品質與定期檢查抓取狀況,就能讓你的網站脫離「隱形模式」,真正邁向 SEO 成功的第一步。



















